Road 2 NLP- Word Embedding词向量(Word2vec)
1. 参考资料
- Word2vec 开山之作1:《Distributed Representations of Sentences and Documents》,作者Mikolov
- Word2vec 开山之作2:《Efficient estimation of word representations in vector space》,作者Mikolov
- Word2vec论文讲解:《word2vec Parameter Learning Explained》,作者Xin Rong
- 知乎专栏文:[NLP] 秒懂词向量Word2vec的本质
- 博客文章:word2vec原理(三) 基于Negative Sampling的模型
以下为[NLP] 秒懂词向量Word2vec的本质 的推荐资料分析:
1. Mikolov 两篇原论文:
『Distributed Representations of Sentences and Documents』
贡献:在前人基础上提出更精简的语言模型(language model)框架并用于生成词向量,这个框架就是 Word2vec
『Efficient estimation of word representations in vector space』
贡献:专门讲训练 Word2vec 中的两个trick:hierarchical softmax 和 negative sampling
优点:Word2vec 开山之作,两篇论文均值得一读
缺点:只见树木,不见森林和树叶,读完不得要义。
这里『森林』指 word2vec 模型的理论基础——即 以神经网络形式表示的语言模型
『树叶』指具体的神经网络形式、理论推导、hierarchical softmax 的实现细节等等
2. 北漂浪子的博客:『深度学习word2vec 笔记之基础篇』
优点:非常系统,结合源码剖析,语言平实易懂
缺点:太啰嗦,有点抓不住精髓
3. Yoav Goldberg 的论文:『word2vec Explained- Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method』
优点:对 negative-sampling 的公式推导非常完备
缺点:不够全面,而且都是公式,没有图示,略显干枯
4. Xin Rong 的论文:『word2vec Parameter Learning Explained』:
!重点推荐!
理论完备由浅入深非常好懂,且直击要害,既有 high-level 的 intuition 的解释,也有细节的推导过程
一定要看这篇paper!一定要看这篇paper!一定要看这篇paper!
5. 来斯惟的博士论文『基于神经网络的词和文档语义向量表示方法研究』以及他的博客(网名:licstar)
可以作为更深入全面的扩展阅读,这里不仅仅有 word2vec,而是把词嵌入的所有主流方法通通梳理了一遍
6. 几位大牛在知乎的回答:『word2vec 相比之前的 Word Embedding 方法好在什么地方?』
刘知远、邱锡鹏、李韶华等知名学者从不同角度发表对 Word2vec 的看法,非常值得一看
7. Sebastian 的博客:『On word embeddings - Part 2: Approximating the Softmax』
详细讲解了 softmax 的近似方法,Word2vec 的 hierarchical softmax 只是其中一种
对比上述所有资料,重点看《word2vec Parameter Learning Explained》,并期望基于此文完全弄懂Word2vec原理。
2. Word2vec原理(《word2vec Parameter Learning Explained》)
Word2vec = CBOW + Skip-Gram(Hierarchical Softmax & Negative Sampling)
其中,
- CBOW:上下文词语 预测 中心词
- Skip-Gram:中心词 预测 上下文词语
2.1. One-Word Context(CBOW & Skip-Gram一致的最简单情形)
- 问题描述:最简单情形,input => 当前词,output => 下一个词,即输入当前词预测下一个词
- 模型框架
为方便解说,这里不直接引用原论文图,自己重新Visio画。
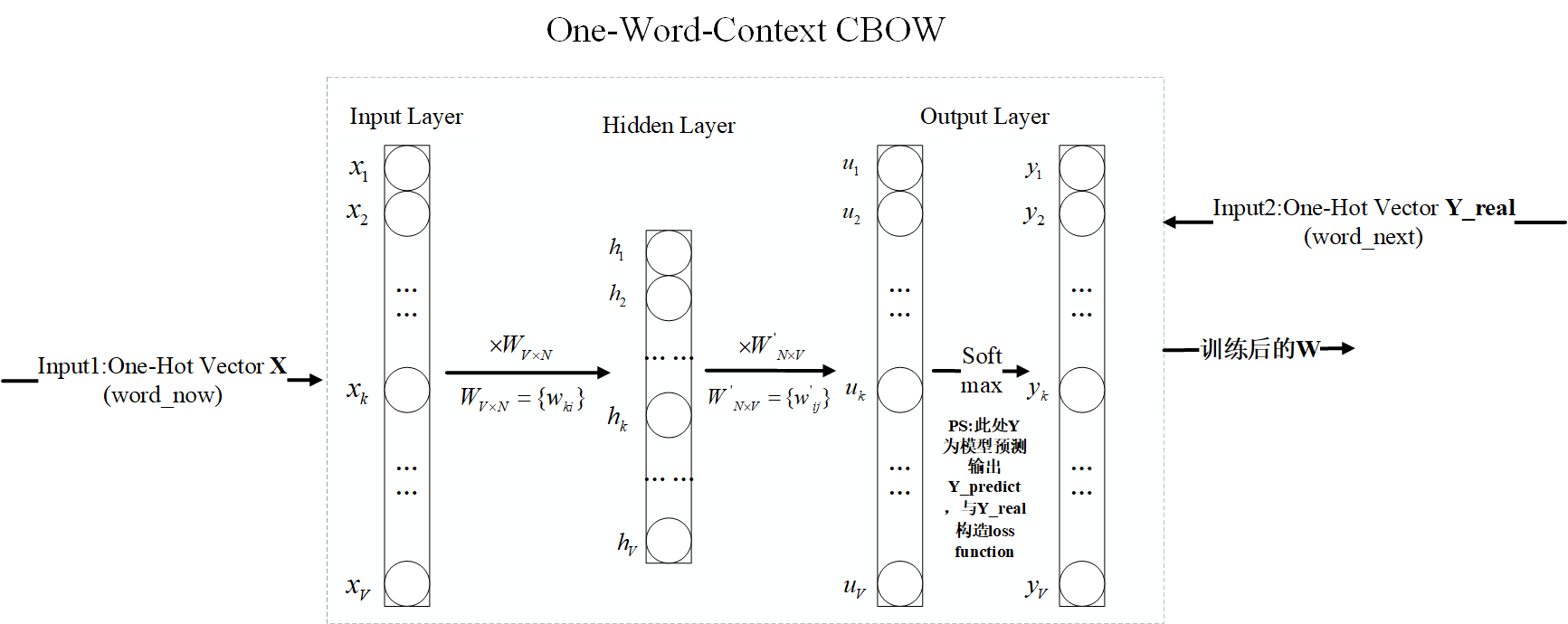
(1). Input layer:输入:$X_{V×1} = OneHot(wordNow)$(模型外部输入input1), 初始化随机矩阵$W_{V×N}$(PS:$W_{V×N}$第w行的行向量 $V_w$,称作输入向量(input vector),Size为:1×N,N为词向量维度,V>>N)。输出:$h_{N×1}=W_{V×N}^{T}X_{V×1}$。
(2). Hidden layer:输入:Input层输出$h_{N×1}$,初始化随机矩阵 $W^{‘}_{V×N}$(PS:$W^{‘}_{V×N}$的第w列的列向量 , $V^{‘}_w$称作输出向量(output vector),Size为:N×1)。输出:$u_{V×1}=W^{‘T}_{N×V}h_{N×1}$。
(3). Output layer:输入:Hidden层输出$u$。输出:$y_j = \frac{exp(u_j)}{\sum_{a=1}^{V}exp(u_a)}$(预测输出Y_predict)。实际输出(模型外部输入input2)$YReal=OneHot(wordNext)$。Y_predict & Y_real构造loss function更新权值$W$、$W^{‘}$。
输入向量矩阵$W$、输出向量矩阵$W^{‘}$,均可作为词语的词向量表示。但是Word2vec采用输入向量矩阵$W$。原因:输出向量矩阵$W^{‘}$更新代价大,以下为《word2vec Parameter Learning Explained》原文
1. 英文原文:
Learning the input vectors is cheap; but learning the output vectors is very expensive.
From the update equations (22)and (33), we can and that, in order to update v_w , for each training instance, we have to iterate through every word w_j in the vocabulary, compute their net input u_j , probability prediction y_j (or y_{cj} for skip-gram), their prediction error e_j (or EI_j for skip-gram), and finally use their prediction error to update their output vector v^{'}_{j}.
Doing such computations for all words for every training instance is very expensive,
making it impractical to scale up to large vocabularies or large training corpora.
To solve this problem, an intuition is to limit the number of output vectors that must be updated per training instance. One elegant approach to achieving this is hierarchical softmax; another approach is through sampling, which will be discussed in the next section.
2. 中文翻译(Google):
学习输入向量很便宜; 但学习输出向量非常昂贵。
从更新方程(22)和(33),我们可以和那个为了更新v_w,对于每个训练实例,我们必须遍历词汇表中的每个单词w_j,计算它们的净输入u_j,概率预测y_j( 或者y_ {cj}用于skip-gram),它们的预测误差e_j(或者用于skip-gram的EI_j),并且最后使用它们的预测误差来更新它们的输出向量v^{'}_{j}。
对每个训练实例的所有单词进行此类计算非常昂贵,
使扩展到大型词汇表或大型培训语料库变得不切实际。
为了解决这个问题,直觉是限制每个训练实例必须更新的输出向量的数量。 实现这一目标的一个优雅方法是分层softmax; 另一种方法是通过抽样,这将在下一节中讨论。
这段文字有2个结论:(1)训练输入向量更容易;(2)Hierarchical Softmax & Negative Sampling 方法都是用于更新输出向量的。
- 模型本质
通过上面对3层分析,Word2vec模型本质:训练更新权值矩阵W,即输入向量矩阵,作为词向量表。因为矩阵W尺寸为V×N,则每一行的行向量对应着该位置的词的Word2vec词向量
- 模型例子
词库为:“我”、“喜欢”、“苹果”,对应的One-Hot词向量分别为[1,0,0]、[0,1,0]、[0,0,1]。输入到One-Word-Context CBOW模型,取词向量维度N=2(一般V>>N,此处V=3,作为例子取N=2)经过训练得到W矩阵如下:
尺寸为V x N,即3 x 2。因此,“我”的Word2vec词向量为[0.2, 0.4],“喜欢”的Word2vec词向量为[0.6, 0.7],“苹果的”Word2vec词向量为[0.8, 0.1]。
- loss function
Output层的预测输出:$y_j = \frac{exp(u_j)}{\sum_{a=1}^{V}exp(u_a)}$
联合额外公式:$h_{N×1}=W_{V×N}^{T}X_{V×1}=v_{wI}^{T}$、 PS:$u_j$为标量,$V_w^{‘T}$尺寸为1×N。
推导出:
令loss function为最大似然函数:
- 模型训练:参数更新(BP/SGD算法)
PS:此处涉及矩阵求导。。也不是很懂,尽可能去理解。部分公式可能编辑有问题,能理解原意即可。
(1). $W^{‘}$更新:$u→W^{‘}$(output→hidden)
$u$:$\frac{\partial E}{\partial u_j}=y_j - t_j := e_j$(y$_j$为实际输出;$t_j=1(j=j^{real})$,$j$为预测输出y位置,$j^{real}$后者则为实际输出;$e_j为$预测error)
$W^{‘}$:$\frac{\partial E}{\partial w_{ij}}=\frac{\partial E}{\partial u_j} - \frac{\partial u_j}{\partial w_{ij}} := e_j * h_i$
更新公式:
$V_{wj}$为$W^{‘}$矩阵的第$j$列的列向量,即输出向量。
(2). $W$更新:$h→W$(hidden→input)
$h:\frac{\partial E}{\partial h_i}=\sum_{j=1}^{V}{\frac{\partial E}{\partial u_j}\frac{\partial u_j}{\partial h_i}} =\sum_{j=1}^{V}{e_j * w^{‘}_{ij}}:= Z_i$
$W:\frac{\partial E}{\partial w_{ki}}=\frac{\partial E}{\partial h_i}\frac{\partial h_i}{\partial w_{ki}}=Z_i*X_k$
PS:$\frac{\partial E}{\partial W}=X_{V×1}叉乘Z$,叉乘定义:$a 叉乘 b = |a||b|sin(a,b)$。由于$X$仅有唯一位置非0,则$\frac{\partial E}{\partial W}$仅有唯一的一行非零向量,其值为$Z^T$
更新公式:
$V_{wI}$为$W$矩阵的第$i$行的行向量,即输入向量。
至此One-Word-Context所有原理结束,接下来的Multi-Word CBOW & Skip-Gram模型原理和这个差别不大,仅在此基础上修改部分公式。
2.2 CBOW(Continuous Bag-of-Word Model)
2.2.1 Multi-Word Context
Multi-Word的意思是说,多个上下文词语 => 中心词(当前词)。CBOW,即为One-Word-Context的Input layer扩展。此处直接借用文献图
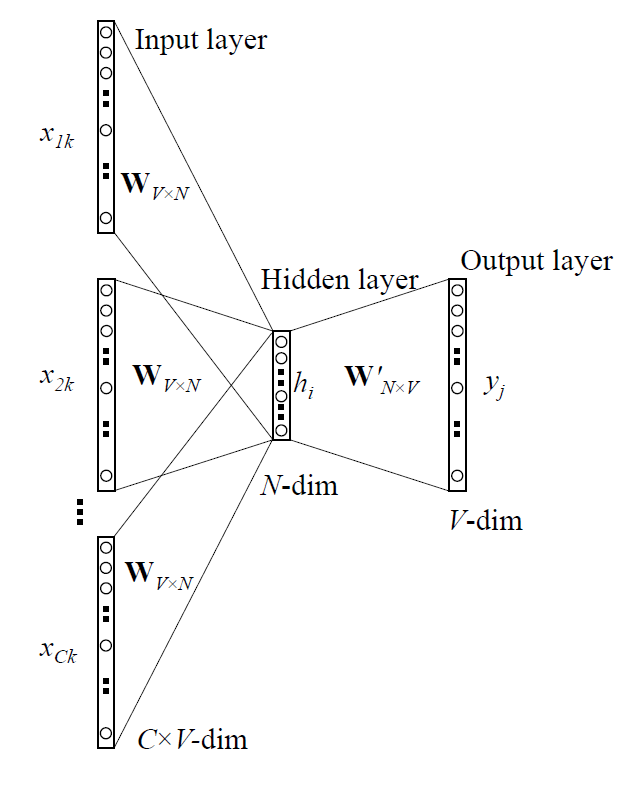
- 和One-Word-Context的唯一区别:$h=\frac{1}{C}W^{T}(x_{1}+x_{2}+···+x_{C})=\frac{1}{C}(V_{w1}+V_{w2}+···+V_{wC})^{T}$,即取上下文总共C个词语的One-Hot编码,上下文词数分别为$\frac{2}{C}$,求平均所有Input layer输入。
2.3 Skip-Gram
同CBOW理,Skip-Gram,即为One-Word-Context的Output layer扩展。
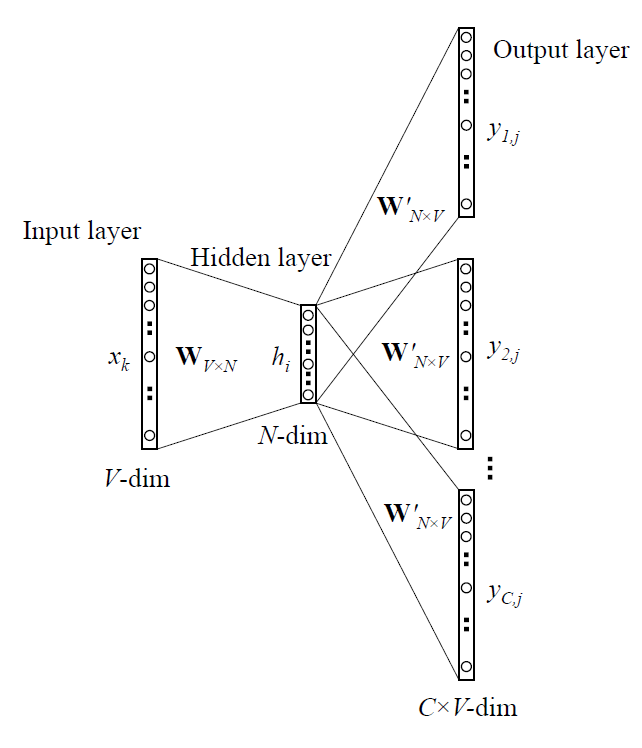
- 和One-Word-Context的唯一区别:loss function
2.4 Hierarchical Softmax
分层softmax(Hierarchical Softmax)本质是优化版softmax,即引入Hierarchical Softmax仅是代替原来softmax结构,优化output vector计算复杂度。
- 原softmax:$y_{i}=\frac{exp(x_i)}{\sum_{a=1}^{V}{exp(x_a)}}$,其中$x_i$为输入向量$X_{V×1}$第$i$位数值标量,$y_i$则为对应输出,输出向量$Y_{V×1}$
可以看出,计算一次$y_i$需要知道所有$x_{i}$值。复杂度为O(V)。
Hierarchical Softmax:引入霍夫曼树,首先依据词频构建霍夫曼树,词语节点都是叶节点。q
如下图为论文原图
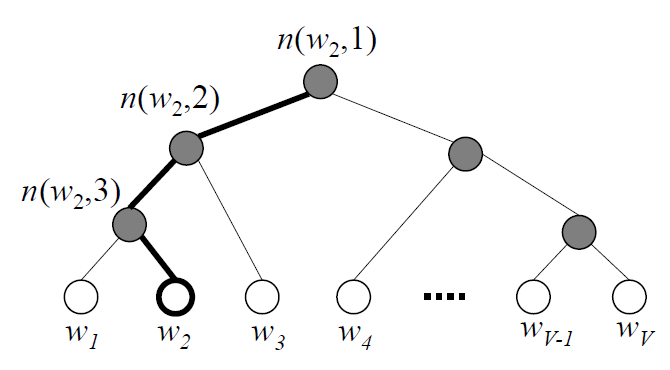
在Hierarchical Softmax中,举例如上图,计算词语$w_{2}$对应的softmax近似概率(H-softmax计算近似值):
其中$v^{‘T}_{n(w_{2},1)}、v^{‘T}_{n(w_{2},2)}、v^{‘T}_{n(w_{2},3)}$分别为3个节点参数,需要训练更新。
且
为表示方便,上图例子公式如下
其中,$σ(x)$函数为二元逻辑回归函数$y=\frac{1}{1+exp(-X^{T}*θ)}$。
容易看出,上面计算$y_{i}$公式计算复杂度下降,不再需要计算V步,仅需要$log(V)$步(即$w_2$路径长)。所以Hierarchical Softmax的计算复杂度为$O(log(V))$
参数更新:
2.5 Negative Sampling
参考博客文章word2vec原理(三) 基于Negative Sampling的模型,总结如下。
Negative Sampling,是代替H-softmax方法的另一种优化计算output vector的方法。如其名,这方法涉及采样(Sampling)。
大致原理:现有训练样本,包括当前中心词$w$和C个上下文词$Context(w)$(上下文分别$\frac{2}{C}$个词),命名为正例。对词库进行负采样(Negative Sampling),得到非$w$的N个中心词$w_i(i=1,2,···,N)$,将N个样本$w_i、Context(w)(i=1,2,···,N)$(注意:$Context(w)$没变,只是中心词w变了)一起作为训练样本,命名为负例。正例 & 负例 => loss function。
2个问题:如上原理介绍,有2个问题:
- Q1:如何Negative Sampling获得非$w$的N个中心词$w_i(i=1,2,···,N)$?
- Q2:如何根据正负样例构造loss function?
Q1:Negative Sampling
词库词语数量为V,引入长度为1的标准线L,将其分为V份,每一小段对应1个词语。Word2vec中,定义每个词语对应的长度为$len(w_{i})=\frac{count(w_{i})^{3/4}}{\sum_{a=1}^{V}{count(w_{i})^{3/4}}}$,且有$\sum_{a=1}^{V}{len(w_i)=1}$。
采样前,将标准线L等分为M份(M>>V,Word2vec中M取$10^{8}$),因此每个词长可以对应若干个M小份长度。如下图为博客图片:
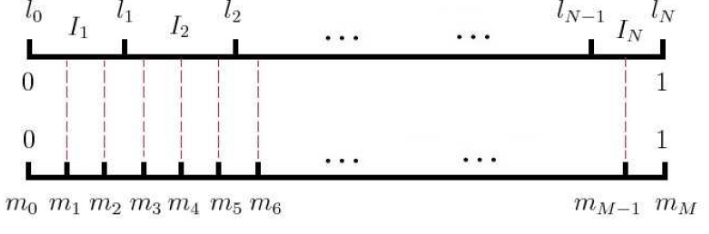
采样时,随机在M个位置中采样N个$m_{i}$位置,则每一个位置肯定落入对应的1个词语。注意:采样词不要重复且不能和当前中心词$w$一样。
Q2:loss function
定义当前词$w$为$w_{0}$,正例为$[w_{0},Context(w_{0})]$,负例为$[w_{i},Context(w_{i})](i=1,2,···,N)$。
根据逻辑函数有正例概率:
负例概率:
最大化公式:
似然函数:
log似然:
参数更新:(SGD算法)
类似前面操作,最终有参数$x_{w_0}, \theta^{w_i}, i=0,1,..N$更新公式。具体参考word2vec原理(三) 基于Negative Sampling的模型。
3. 总结
Word2vec = CBOW + Skip-Gram(Hierarchical Softmax & Negative Sampling)
其中,CBOW:上下文词语 预测 中心词;Skip-Gram:中心词 预测 上下文词语
Word2vec词向量仅是模型副产品,即输入向量矩阵W